Sorting Algorithms
Sorting is the process of arranging the elements of a list or array in a specific order, typically in ascending or descending order
Here is how we formally define the sorting problem:
- Input: A sequence of
numbers - Output: A permutation (reordering)
of the input sequence such that
List of sorting algorithms:
- Bubble:
(also known as Simple Sort) - Insertion:
- Selection:
- Heap Sort:
- Merge Sort:
- Quick Sort:
- Tree Sort:
- Shell Sort:
- Count Sort:
- Bucket/Bin Sort :
- Radix Sort :
In the above list
1-8are called Comparison based Sorts, And9-11are called Index based Sorts
Check out the Comparison sorts section for summary of the above algorithms
Criteria For Analysis
Number of Comparisons
Number of Swaps
Adaptive: Less time to sort an already sorted list
An adaptive sorting algorithm is one that takes advantage of the existing order of the input data to improve its efficiency. If an algorithm is adaptive, it performs fewer comparisons or swaps when dealing with partially sorted data
Efficient for data sets that are already substantially sorted
Stability: A sorting algorithm is stable if it maintains the relative order of equal elements in the sorted output as they were in the original input
In other words, if you have two equal elements
AandB, andAappears beforeBin the input, a stable sorting algorithm will ensure thatAstill appears beforeBin the sorted outputDoes not change the relative order of elements with equal keys
Extra Memory
Bubble Sort
Bubble Sort (a.k.a Simple Sort) is a straightforward sorting algorithm that repeatedly steps through the list, compares adjacent elements, and swaps them if they are in the wrong order. The pass through the list is repeated until the list is sorted
Steps:
Start with an unsorted list of elements
Compare the first element with the second element. If the first element is greater than the second element, swap them
Move to the next pair of elements (second and third) and repeat step 2
Continue this process for all adjacent pairs of elements in the list, comparing, and swapping as necessary
- After the first pass, the largest element will have "bubbled up" to the end of the list
Repeat steps 2 to 4 for a total of
passes, where is the number of elements in the list. On each pass, the largest unsorted element will move to the end of the list After completing all passes, the list will be sorted
Pseudocode:
function bubbleSort(arr) // arr is 0 indexed array
n = length(arr)
for i from 0 to n - 1
for j from 0 to n - i - 1
if arr[j] > arr[j + 1]
swap(arr[j], arr[j + 1])Example:
Let's say you have an unsorted list: [5, 2, 9, 5, 1]

- Pass 1: Swap
5and2, then9and5, then9and1:[2, 5, 5, 1, 9] - Pass 2:
[2, 1, 5, 5, 9] - Pass 3:
[1, 2, 5, 5, 9]is sorted
Analysis:
For an array of size
- Number of Passes:
- Max Number of Comparisons:
to - Max Number of Swaps:
to
Time complexity:
- Best case:
- Average case:
- Worst case:
By using a flag we can make it Adaptive
- For an Adaptive sort it will perform:
- Comparisons:
- Swaps:
- Performance:
- Comparisons:
Note:
Bubble sort is Adaptive and Stable
It can be used to get some number of elements sorted, like finding the largest (or smallest if descending) number in 1 pass (the last element)
Implementations:
void Bubble_Sort(int A[], int n) {
int i, j, temp = 0;
int flag; // makes the sort Adaptive
for (i = 0; i < n - 1; i++) {
flag = 0;
for (j = 0; j < n - i - 1; j++) {
if (A[j] > A[j + 1]) {
temp = A[j + 1];
A[j + 1] = A[j];
A[j] = temp;
flag = 1;
}
}
if (flag == 0)
break;
}
}Insertion Sort
Insertion Sort is a simple sorting algorithm that builds the final sorted array one element at a time. It's based on the idea of iteratively inserting elements from the unsorted portion of the array into their correct positions within the sorted portion. This process continues until all elements are inserted and the entire array is sorted
Steps:
Initial State: The algorithm considers the first element as the initially sorted portion and the remaining elements as the unsorted portion
Iterative Insertion: For each element in the unsorted portion, the algorithm compares it to the elements in the sorted portion from right to left. It finds the correct position for the element within the sorted portion by shifting larger elements to the right
Insertion: Once the correct position is found, the element is inserted into its place within the sorted portion
Repeat: Steps 2 and 3 are repeated for all remaining elements in the unsorted portion until all elements have been inserted into the sorted portion
Pseudocode:
// A is 0 indexed array
for i = 1 to A.length:
key = A[i]
// Insert A[i] into the sorted sequence A[1..i-1]
j = i - 1
while j > 0 and A[j] > key:
A[j + 1] = A[j]
j = j - 1
A[j + 1] = keyExamples:
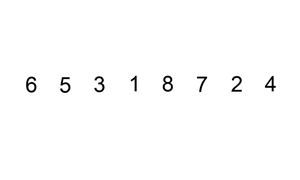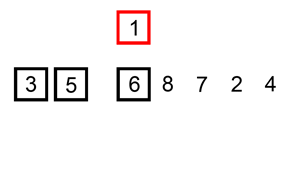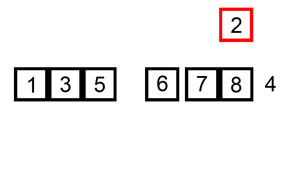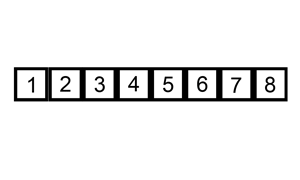
Let's say you have an unsorted list: [5, 2, 9, 1, 5]
- Pass 1:
[2, 5, 9, 1, 5] - Pass 2:
[2, 5, 9, 1, 5] - Pass 3:
[1, 2, 5, 9, 5] - Pass 4:
[1, 2, 5, 5, 9]
Analysis:
Best-Case Scenario:
- Input: The input array is already sorted
- Time Complexity:
O(n) - Explanation: Each element is already in its correct position, so the algorithm only compares each element with the one before it and makes no swaps. The inner loop of the insertion sort algorithm will only execute once for each element. Therefore, it only performs
n-1comparisons, resulting in a linear time complexity - Max Number of Comparisons:
n - 1->O(n) - Max Number of Swaps:
0->O(1)
Worst-Case Scenario:
- Input: The input array is sorted in reverse order
- Time Complexity:
O(n^2) - Explanation: In the worst case, each new element is smaller than all the elements already sorted. This requires the algorithm to compare the new element with all previous elements and shift them to the right, leading to a quadratic number of comparisons and swaps
For an array of size
nat worst case:- Number of Passes:
n-1 - Max Number of Comparisons:
(n * (n - 1)) / 2->O(n^2) - Max Number of Swaps:
(n * (n - 1)) / 2->O(n^2)
Average-Case Scenario:
- Input: The input array is in a random order
- Time Complexity:
O(n^2) - Explanation:
- On average, each element in the array is compared and potentially swapped with about half of the elements before it
- Specifically, for each element, about half of the previous elements are expected to be larger and need to be shifted to make room for the new element
- Since this happens for each of the
nelements, the total number of comparisons and shifts sums to about, which still results in a quadratic time complexity, O(n^2)
| Bubble Sort | Insertion Sort | Cases | |
|---|---|---|---|
| Min Comparison | O(n) | O(n) | Already Sorted |
| Max Comparison | O(n^2) | O(n^2) | Sorted in Reverse |
| Min Swap | O(1) | O(1) | Already Sorted |
| Max Swap | O(n^2) | O(n^2) | Sorted in Reverse |
| Adaptive | Yes | Yes | |
| Stable | Yes | Yes | |
| Linked List | - | Yes | |
| k Passes | Yes | No |
Characteristics:
Insertion Sort is particularly efficient when dealing with small arrays or partially sorted arrays, as the number of comparisons and shifts is relatively small in those cases
More efficient in practice than most other simple quadratic algorithms such as selection sort or bubble sort
It's in-place sorting algorithm, meaning it doesn't require additional memory space proportional to the input size for sorting and with, at most, a constant number of them stored outside the array at any time
Although the best-case time complexity of Insertion Sort is
O(n)and the worst-case isO(n^2), the average-case also falls intoO(n^2), reflecting that Insertion Sort generally performs similarly to its worst-case on typical, randomly ordered inputsThis quadratic time complexity means that Insertion Sort is less efficient on average compared to more advanced sorting algorithms like Merge Sort or Quick Sort, especially as the input size grows
Insertion is better for Linked List than Arrays
By nature it is Adaptive
It is Stable
Online: can sort a list as it receives it
Loop Invariant
Loop invariant: At the start of each iteration of the for loop of lines 1–8, the subarray A[1..j-1] consists of the elements originally in A[1..j-1], but in sorted order
We use loop invariants to help us understand why an algorithm is correct. We must show three things about a loop invariant:
- Initialization: It is true prior to the first iteration of the loop
- Maintenance: If it is true before an iteration of the loop, it remains true before the next iteration
- Termination: When the loop terminates, the invariant gives us a useful property that helps show that the algorithm is correct
When the first two properties hold, the loop invariant is true prior to every iteration of the loop
Selection Sort
Selection sort is in-place comparison-based algorithm in which the list is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire list
The smallest (or largest) element is selected from the unsorted array and swapped with the leftmost element, and that element becomes a part of the sorted array. This process continues moving unsorted array boundary by one element to the right
Steps:
Initial State: The algorithm starts with the entire array being unsorted and an empty sorted portion
Find the Minimum: In each iteration, the algorithm scans the unsorted portion of the array to find the minimum (or maximum) element
Swap: Once the minimum (or maximum) element is found, it's swapped with the leftmost element in the unsorted portion. This effectively moves the selected element to the end of the sorted portion
Expand Sorted Portion: After the swap, the sorted portion grows by one element, and the unsorted portion shrinks by one element
Repeat: Steps 2 to 4 are repeated until the entire array is sorted. The sorted portion gradually expands while the unsorted portion shrinks until there are no more elements left in the unsorted portion
Final State: The array is fully sorted
Pseudocode: Sort in ascending order
function selectionSort(arr) // arr is 0 indexed array
n = length(arr)
for i from 0 to n-2 // The last element will be in the correct position after n-1 iterations
minIndex = i
for j from i+1 to n-1
if arr[j] < arr[minIndex]
minIndex = j
if minIndex != i
swap(arr[i], arr[minIndex])Example:
Let's say you have an unsorted list: [5, 2, 9, 5, 1] and you want to sort it in ascending order

- Pass 1: Find the smallest, which is
1and swap with left most5:[1, 2, 9, 5, 5] - Pass 2:
[1, 2, 9, 5, 5] - Pass 3:
[1, 2, 5, 9, 5] - Pass 4:
[1, 2, 5, 5, 9] - Pass 5:
[1, 2, 5, 5, 9]is sorted
Analysis:
Each element is compared in every operation, with number of operations same as the number of elements
- With each operation an element is moved to the new array, so one less element to be compared in the next operation. On an average,
elements are compared for each operation. Thus, the runtime is . But constants like are ignored in Big-O. So the runtime is written as
For an array of size
- Number of Passes:
- Max Number of Comparisons:
to - Max Number of Swaps:
to
Time complexity:
- Best case:
- Average case:
- Worst case:
Note:
It is not Stable: does not guarantee stability
- When selecting the minimum (or maximum) element to be placed in its correct position, Selection Sort doesn't consider the relative order of equal elements. As a result, if there are equal elements in the array, their order might change during the sorting process
It is not Adaptive: Its time complexity remains the same regardless of the input's initial order
- It doesn't take advantage of any pre-existing order in the data. It always scans the entire unsorted portion of the array to find the minimum (or maximum) element, regardless of whether the array is partially sorted or not
We get smallest (or largest if descending) number after just 1 pass (the first element)
Implementations:
def find_smallest(arr):
smallest = arr[0]
smallest_index = 0
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
# Selection Sort
def selection_sort(arr):
newArr = []
for i in range(len(arr)):
smallest = find_smallest(arr)
newArr.append(arr.pop(smallest))
return newArrQuick Sort
It uses Divide & Conquer technique
Partitioning procedure
Not suited for sorted list or reverse sorted list
Inductive proofs
Randomized QuickSort
Selection Exchange Sort
Partition Exchange Sort
Merge Sort
Merge Sort is a popular comparison-based sorting algorithm that follows the Divide-and-Conquer Algorithm strategy to efficiently sort an array or list of elements. It works by recursively dividing the array into smaller sub-arrays, sorting those sub-arrays, and then merging them back together to create a sorted final array
Steps:
Divide: The original array is recursively divided into smaller sub-arrays until each sub-array contains only one element or is empty
Conquer: The individual elements or small sub-arrays are already sorted by definition. This is the base case of the recursion
Merge: The sorted sub-arrays are then merged back together in a way that maintains their order. This merging process combines two sorted arrays into a single sorted array
In each step, it sorts a sub-array A[p:r] starting with the entire array A[1:n] and recursing down to smaller and smaller sub-arrays:
Divide the sub-array
A[p:r]to be sorted into two adjacent sub-arrays, each of half the size. To do so, compute the midpointqofA[p:r](taking the average ofpandr), and divideA[p:r]into sub-arraysA[p:q]andA[q+1:r]Conquer by sorting each of the two sub-arrays
A[p:q]andA[q+1:r]recursively using merge sortCombine by merging the two sorted sub-arrays
A[p:q]andA[q+1:r]back intoA[p:r], producing the sorted answer
The recursion "bottoms out" - it reaches the base case - when the sub-array
A[p:r]to be sorted has just 1 element, that is, whenpequalsrThe key operation of the merge sort algorithm occurs in the "combine" step, which merges two adjacent, sorted sub-arrays
The merge operation is performed by the auxiliary procedure
MERGE(A, p, q, r), whereAis an array andp,q, andrare indices into the array such thatp <= q < rThe procedure assumes that the adjacent sub-arrays
A[p:q]andA[q+1:r]were already recursively sortedIt merges the two sorted sub-arrays to form a single sorted sub-array that replaces the current sub-array
A[p:r]
Pseudocode:
Merge(A, p, q, r):
nl = q - p + 1 // length of A[p:q]
nr = r - q // length of A[q+1:r]
let L[0:nl - 1] and R[0:nr - 1] be new arrays
for i = 0 to nl - 1: // copy A[p:q] into L[0:nl - 1]
L[i] = A[p + i]
for j = 0 to nr - 1: // copy A[q+1:r] into R[0:nl - 1]
L[j] = A[q + j + 1]
i = 0 // i indexes the smallest remaining element in L
j = 0 // j indexes the smallest remaining element in R
k = p // k indexes the location in A to fill
// As long as each of the arrays L and R contains an unmerged element,
// copy the smallest unmerged element back into A[p:r]
while i < nl and j < nr:
if L[i] <= R[j]:
A[k] = L[i]
i = i + 1
else:
A[k] == R[j]
j = j + 1
k = k + 1
// Having gone through on of L and R entirely, copy the
// remainder of the other to the end of A[p:r]
while i < nl:
A[k] = L[i]
i = i + 1
k = k + 1
while j < nr:
A[k] = R[j]
j = j + 1
k = k + 1
// A is an array, p is starting index (0), r is the length of array - 1
Merge-Sort(A, p, r):
if p >= r: // zero or one element?
return
q = floor((p + r)/2) // midpoint of A[p:r]
Merge-Sort(A, p, q) // recursively sort A[p:q]
Merge-Sort(A, q + 1, r) // recursively sort A[q+1:r]
// Merge A[p:q] and A[q+1:r] into A[p:r]
Merge(A, p, q, r)- Alternative, creating a new array:
function mergeSort(arr):
if length(arr) <= 1:
return arr
mid = length(arr) / 2
// Divide the array into left and right sub-arrays
left = arr[0:mid]
right = arr[mid:end]
// Recursively sort the left and right sub-arrays
left = mergeSort(left)
right = mergeSort(right)
// Merge the sorted sub-arrays
sortedArray = merge(left, right)
return sortedArray
function merge(left, right):
result = []
leftIndex = 0
rightIndex = 0
while leftIndex < length(left) and rightIndex < length(right):
if left[leftIndex] <= right[rightIndex]:
result.append(left[leftIndex])
leftIndex++
else:
result.append(right[rightIndex])
rightIndex++
// Add remaining elements from both arrays
while leftIndex < length(left):
result.append(left[leftIndex])
leftIndex++
while rightIndex < length(right):
result.append(right[rightIndex])
rightIndex++
return resultAnalysis:
The running time of an algorithm on an input of size n by T(n), worst-case running time:
Divide: The divide step just computes the middle of the sub-array, which takes constant time. Thus,
D(n) = θ(1)Conquer: Recursively solving two sub-problems, each of size
n/2, contributes2T(n/2)to the running time (ignoring the floors and ceilings)Combine: Since the MERGE procedure on a n-element sub-array takes
θ(n)time, we haveC(n) = θ(n)Adding
θ(n)to the2T(n/2)term from the conquer step gives the recurrence for the worst-case running timeT(n)of merge sort:
T(n) = 2T(n/2) + θ(n)
T(n) = {
c1 if n <= 1
2T(n/2) + (c2 * n) if n > 1
}
c1 > 0, represents the time required to solve a problem of size 1
c2 > 0, time per array element of the divide and combine stepsUsing the Master Theorem, we can solve this recurrence relation to obtain the time complexity:
a = 2: The number of sub-problemsb = 2: The size of each sub-problemc = 1: The work done in combining the sub-problems
Since log_b(a) = log_2(2) = 1 and c = 1, the case of the Master Theorem that applies is:
T(n) = O(n^log_b(a) * log^k(n))
= O(n^1 * log^0(n))
= O(n log n)Best-Case Scenario:
- Input: The input array is already sorted
- Time Complexity:
O(n log n) - Explanation: Merge sort still divides the array into smaller sub-arrays and merges them back together, but since the sub-arrays are already sorted, the merging process is very efficient
Worst-Case Scenario:
- Input: The input array is sorted in reverse order
- Time Complexity:
O(n log n) - Explanation: This results in the maximum number of comparisons and merges during the algorithm. However, the time complexity remains
O(n log n)because the merging process is still efficient even in the worst case
Average Case Scenario:
- Input: The input array is in a random order
- Time Complexity:
O(n log n) - Explanation: On average, Merge Sort also requires
O(n log n)time. The average case behaves similarly to the best and worst cases due to the algorithm's consistent approach of dividing and merging
Characteristics:
Merge Sort is stable and consistent, and its performance does not degrade with input order
Making it reliable and efficient sorting algorithm, particularly for large datasets
The merging process is the key to Merge sort's efficiency, regardless of the input array's order
It is Stable: During the merging step, when two elements are compared and inserted into the merged array, if they are equal, the element from the left sub-array is inserted before the element from the right sub-array. This maintains the relative order of equal elements, making Merge Sort a stable sorting algorithm
It is Adaptive: Although its basic structure doesn't inherently take advantage of partially sorted data, its time complexity remains efficient even when dealing with partially sorted arrays. The reason is that Merge Sort always divides the array into smaller sub-arrays and eventually merges them. This merging process efficiently combines even small sorted sub-arrays into larger sorted sub-arrays. While not as inherently adaptive as algorithms like Insertion Sort, Merge Sort still performs well with partially sorted data due to its divide-and-conquer nature
Count Sort
- Index based sorting
Bucket/Bin Sort
Shell Sort
Uses Insertion Sort
Comparison Sorts
Here's a comparison of the average-case time complexities of various sorting algorithms:
| Algorithm | Space Complexity | Time Complexity (Worst) | Best | Average | Adaptive | Stable |
|---|---|---|---|---|---|---|
| Bubble Sort | Yes | Yes | ||||
| Selection Sort | No | No | ||||
| Insertion Sort | Yes | Yes | ||||
| Merge Sort | Yes | Yes | ||||
| Quick Sort | No | No (can be made) | ||||
| Heap Sort | No | No | ||||
| Counting Sort | No | Yes | ||||
| Radix Sort | No | Yes | ||||
| Bucket Sort | No | Yes |
Space Complexity:
- All
O(1)are In-place algorithm, hence no additional space is required - Merge sort: Requires additional space for merging sub-arrays, not in-place
- Quick Sort: Recursive algorithm, requires additional space for the call stack
- Counting Sort: Requires additional space for counting array, where
kis the range of input values - Radix Sort: Requires additional space for intermediate arrays, where
kis the number of digits in the maximum number - Bucket Sort: Requires additional space for buckets and intermediate arrays, can be high for small ranges